simaaiprocessmla
This section describes the GStreamer plugin named simaaiprocessmla.
Brief Description
This plugin is used to communicate with the SiMa.ai MLA. The user will only change the configuration file and not the source code when using this plugin.
Config JSON Parameters
{
"version" : 0.1,
"node_name" : "mla-resnet",
"simaai__params" : {
"params" : 15, <========================== NOT USED, NO NEED TO CHANGE
"index" : 1, <============================ NOT USED, NO NEED TO CHANGE
"cpu" : 4, <============================== CPU type used for memory allocation. CONSTANT AND MUST BE SET TO 4
"next_cpu" : 0, <========================= NOT USED, NO NEED TO CHANGE
"out_sz" : 96, <========================== Single buffer size. The buffer size depends on particular model memory layout.
"no_of_outbuf" : 5, <===================== How many output buffers will be created by plugin. Must be greater than 0.
"model_id" : 1, <========================= DEFAULT ONE, NO NEED TO CHANGE
"batch_size" : 1, <======================= Number of frames to process per time
"batch_sz_model" : 1, <=================== Number of frames the particular model supports
"in_tensor_sz": 0, <====================== Input tensor size calculated as `N * H * W * C`. Reflects the input tensor that the particular model accepts . This value will be used only when `batch_size > batch_sz_model`
"out_tensor_sz": 0, <===================== Output tensor size calculated as `N * H * W * C`. Reflects the output tensor that the particular model returns . This value will be used only when `batch_size > batch_sz_model`
"out_type" : 2, <======================= DEFAULT ONE, NO NEED TO CHANGE
"ibufname" : "ev-resnet-preproc", <======= Input buffer name
"inpath" : "/root/ev74_preproc.raw", <==== DEFAULT ONE, NO NEED TO CHANGE
"model_path" : "/path/to/the/model.lm", <= Path to model file
"debug" : 0, <============================ Not used
"dump_data" : 0 <========================= Dump output buffer to file at /tmp
}
}
Description
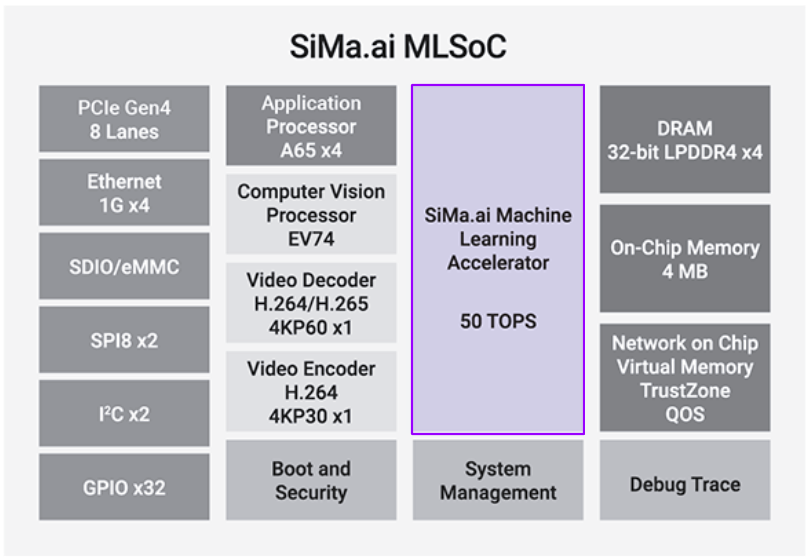
SiMa.ai’s MLA is a dedicated ML accelerator with runtime libraries for executing ML models, providing significant performance improvements for AI applications.
simaaiprocessmla is responsible for the execution of an lm model output from the ModelSDK.
The plugin will load, initialize and run inference on any input feature maps it receives.
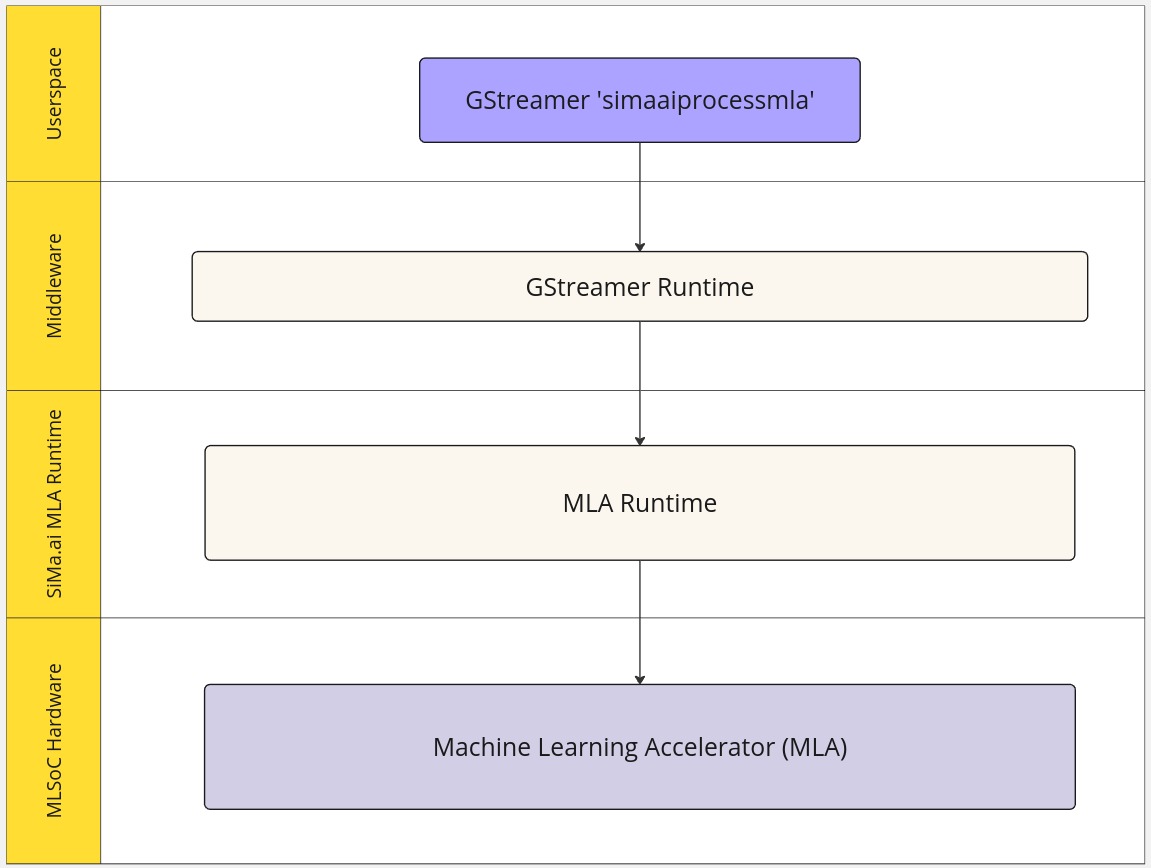
SW Stack
Sample Config JSON
The overall structure for the config json for simaaiprocessmla is similar. Few parameters differ based on the model’s output size.
Let’s say, if we consider a sample Resnet50 Based Model which, classifies the input image into 4 classes. Thus, the output size of the model will be 4 (classes) x 4 (bytes) = 16.
Similarly, we need to provide the ibufname which is input buffer name for simaaiprocessmla.
{
"version": 0.1,
"node_name": "mla-resnet50",
"simaai__params": {
"params": 15,
"index": 1,
"cpu": 4,
"next_cpu": 0,
"out_sz": 16,
"no_of_outbuf": 1,
"model_id": 1,
"in_type": 2,
"batch_size": 1,
"batch_sz_model": 1,
"in_tensor_sz": 0,
"out_tensor_sz": 0,
"out_type": 0,
"ibufname": "ev-gen-preproc",
"inpath": "/root/ev74_preproc.raw",
"model_path": "/path/to/lm/file/model.lm",
"debug": 0,
"dump_data": 0
}
}
Parameter |
Description |
|---|---|
params |
NOT USED, NO NEED TO CHANGE |
index |
NOT USED, NO NEED TO CHANGE |
cpu |
NO NEED TO CHANGE. CONSTANT AND MUST BE SET TO 4 |
next_cpu |
NOT USED, NO NEED TO CHANGE |
out_sz |
Single buffer size. The buffer size depends on particular model memory layout. |
no_of_outbuf |
How many output buffers will be created by plugin. Must be greater than 0. |
model_id |
DEFAULT ONE, NO NEED TO CHANGE |
batch_size |
Number of frames to process per iteration - the desired batch size |
batch_sz_model |
Number of frames the particular model supports - the actual batch size |
in_tensor_sz |
Input tensor size calculated as N * H * W * C. Reflects the input tensor that the particular model accepts. This value will be used only when batch_size > batch_sz_model |
out_tensor_sz |
Output tensor size calculated as N * H * W * C. Reflects the output tensor that the particular model returns. This value will be used only when batch_size > batch_sz_model |
out_type |
DEFAULT ONE, NO NEED TO CHANGE |
ibufname |
Input buffer name from previous plugin |
inpath |
DEFAULT ONE, NO NEED TO CHANGE |
model_path |
Path to lm model file compiled from modelsdk |
debug |
NOT USED, NO NEED TO CHANGE |
dump_data |
Dump output buffer to file at /tmp |
Note
Batching
If the model is trained only to process one frame - user must set
batch_size: 1,batch_sz_model: 1,in_tensor_sz: 0andout_tensor_sz: 0.If model supports batching, and the user wants to process as many frames as model supports (
M) or less: setbatch_size: N,batch_sz_model: M,in_tensor_sz: 0,out_tensor_sz: 0.Where
N<=M
If model supports batching, and the user wants to process more frames than the model supports (
M): setbatch_size: N,batch_sz_model: M,in_tensor_sz: K,out_tensor_sz: P.Where
N>M. AndK = 1 * H * W * Cfor input tensor andP = 1 * H * W * Cfor output tensor.In these cases, the model will run more than once. The number of times it will run will be determined by the formula:
ceil(N / M)
Example Usage
1! simaaiprocessmla config="process_mla.json"
2! simaaiprocessmla config="/path/to/config/json/process_mla.json" !
In the given example, the simaaiprocessmla is taking in the input from ev-gen-preproc.
gst-inspect-1.0 Output
1Plugin Details:
2Name simaaiprocessmla
3Description GStreamer SiMa.ai simaaiprocessmla Plugin
4Filename
5Version
6License LGPL
7Source module gst-plugins-sima
8Binary package GStreamer SiMa.ai simaaiprocessmla Plug-in
9Origin URL https://bitbucket.org/sima-ai/gst-plugins-sima
10
11process2: SiMa.AI Process Plugin
12
131 features:
14+-- 1 elements
Note
Please refer to simaaiprocessmla’s README file for more information.